
This post summarizes three papers at the center of the debate on whether attention is interpretable.
- Attention is not explanation [1]
- Is attention interpretable? [4]
- Attention is not not explanation [5]
In this article, attention is used as an uncountable noun when referred to attention mechanism and used as a countable noun when referred to attention weights.
Attention is Not Explanation
In this work [1], the authors assessed the degree to which attention weights provide meaningful “explanations” for predictions and concluded they largely do not. Meaningful explanation in this paper is a synonym for a faithful explanation, which is unique.
Idea 1: key argument to whether attention provides a faithful explanation
If attention provides a faithful explanation, then
- Attention weights should correlate with feature importance measures, such as results from gradient-based attribution methods and leave-one-out (LOO) methods
- Alternative (even counterfactual) attention weight configurations should yield a different prediction
Finding 1: the correlation between attention and feature importance measures is moderate
Referencing feature importance measures are gradient-based feature importance (
 Image source: [1]
Image source: [1]
They disconnect the computation graph at the attention module, i.e., fixing attention and treating them like an additional set of input. Effectively, this setting answers how much does the output change as we perturb particular inputs by a small amount, while paying the same amount of attention to the said word as originally estimated. The correlation is quantified by Kendall
The observed correlations are modest between BiLSTM attentions with the two baselines. The centrality of observed densities of correlations hovers around or below 0.5 in most of the corpora considered.
One plausible explanation for moderate correlations between attentions and the two baselines is that there exist many irrelevant features (or “noise” as articulated in the paper) because Kendall
Therefore, they concluded that attention weights do not strongly or consistently agree with standard feature importance scores.
Finding 2a: randomly permuting attention weights often induces only minimal changes in output
They scramble the original attention weights and reassigning each value to input features randomly. They find that in many cases this process produces little difference to the prediction. However, for positive samples in specific datasets, this process leads to significant changes in prediction. They conjecture that this is due to a few tokens serving as high precision indicators for the positive classes. (They did not verify whether there exists a dominant attention weight for positive samples even though this is easily done)
 Image source: [1]
Image source: [1]
Finding 2b: adversarial attentions are easy to find
Adversarial attention is a set of attention weights that
- Differ to the original attention weight distribution as much as possible (described by Jensen-Shannon Divergence (JSD))
- Leave the prediction effectively unchanged (described by Total Variation Distance (TVD)) This process may uncover alternative but also plausible explanations. It assumes that attention provides sufficient yet not exhaustive rationales.
 Image source: [1]
Image source: [1]
where equation 1 refers to
where
TVD is total variation distance:
JSD is Jensen-Shannon divergence:
They find that they are frequently able to identify maximally different attention weights that hardly budge model output. They find that adversarial attentions are still relatively easy to find even when attention distributions are peaky, whose alternative distributions are hard to find.
Is Attention Interpretable
The paper [4] investigates the interpretability of attentions under the context of text classification. Interpretability in this paper refers to both plausibility and faithfulness. In this work, the authors investigate whether the attentions’ suggested importance ranking faithfully describes why the model produced its output. They design two experiments based on intuitions on the correlation between feature importance and representation erasure and the correlation between feature importance and decision flips. It should be made explicit that they are intuitions without proves.
Experiment 1: the importance of a single attention weight
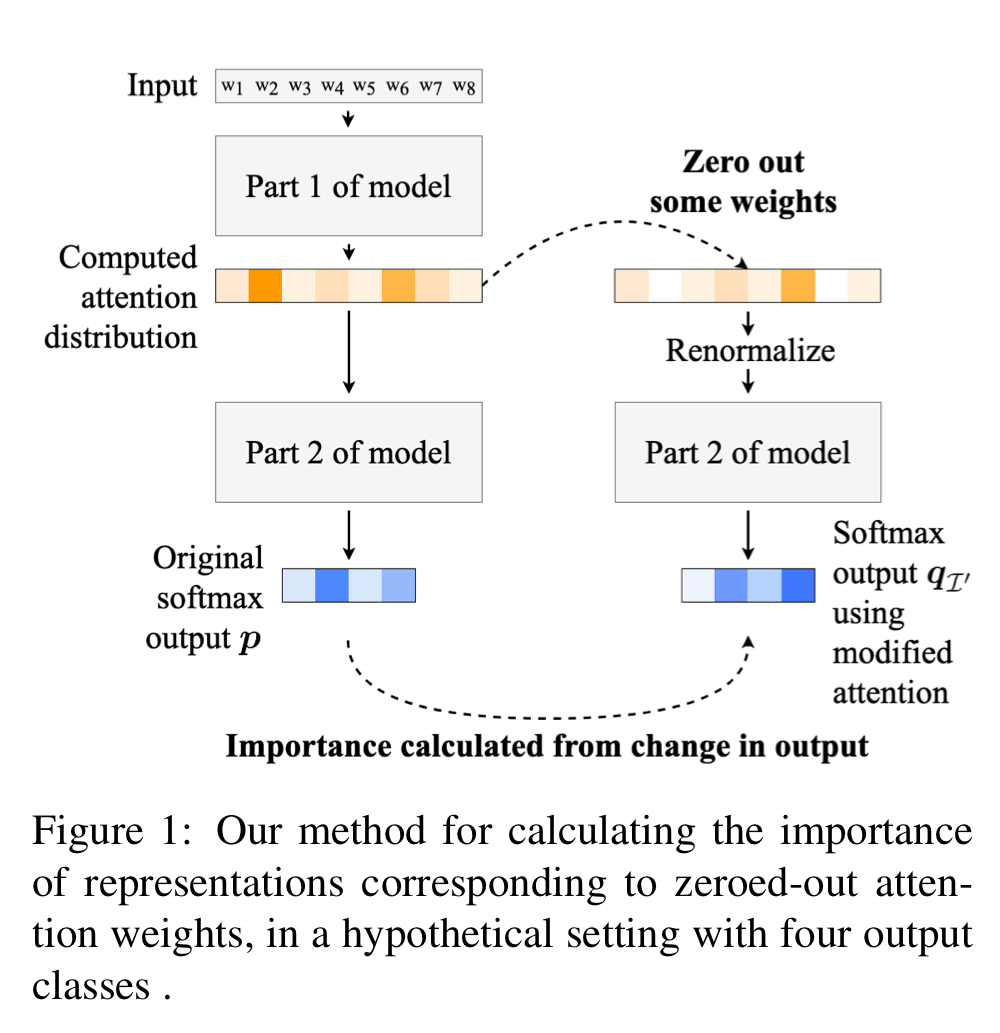 Image source: [4]
Image source: [4]
Experiments in this paper center around the idea of leaving-one-out or leaving-some-out by turning one or some of the attention scores to 0 and see how much change that process will bring about (Figure 1). The change is described by the difference of JS divergence:
where
Intuitively,
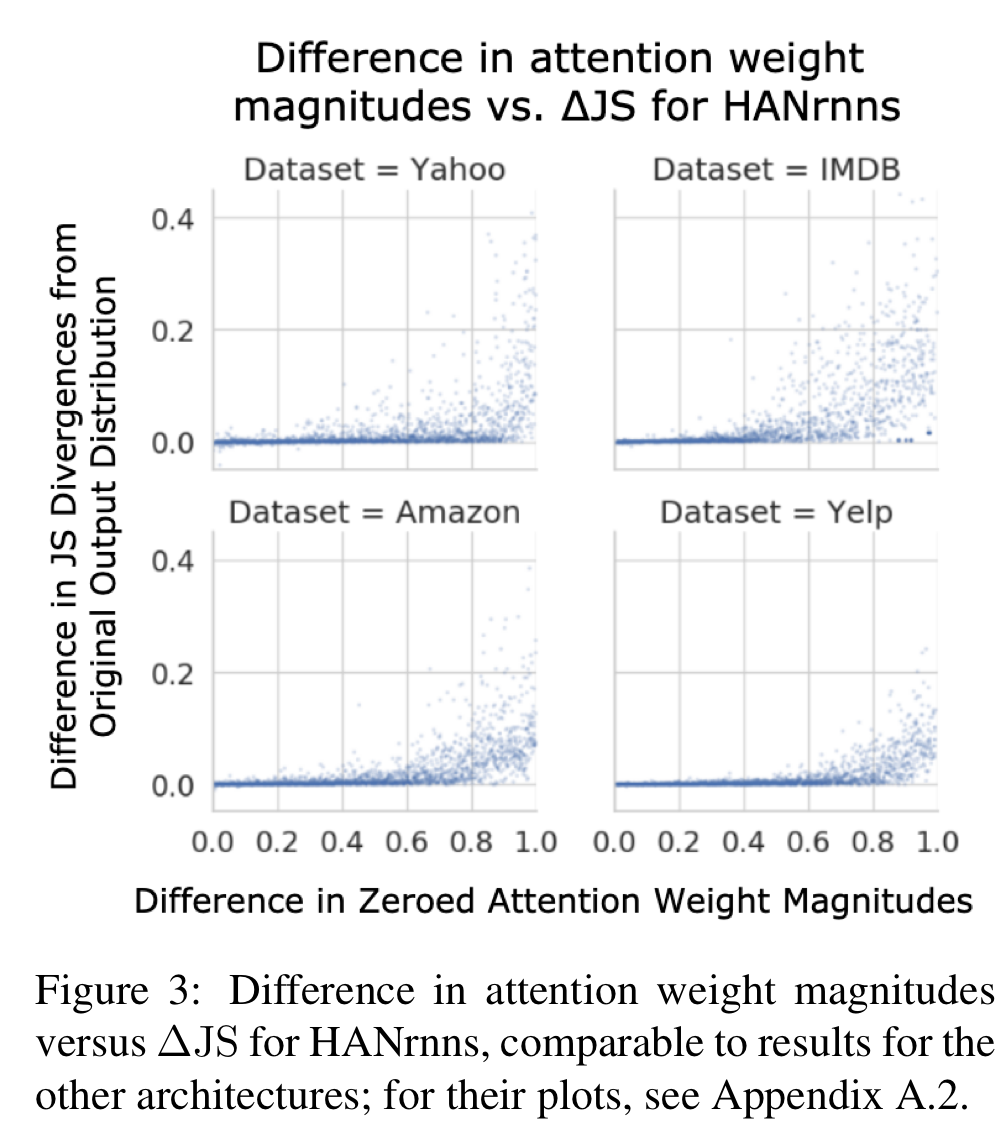 Image source: [4]
Image source: [4]
Observations:
- (+) There are hardly data points with negative
, and negative values are close to 0. - (+) As
increases, the expected and its variance also increase - (-) Most data points with large
have a close-to-zero . This is counterintuitive.
Due to contradicting observations, this experiment is not conclusive. A conjecture they proposed, or a weakness in the study design they acknowledged, is that word representations used in attention calculation are not the original embedding, but contextually fused representations. In other words, the embedding of each word is likely to contain information from its neighboring words. As a result, the model may be able to attend to key information indirectly from unimportant words. Jain and Wallace’s study also is not free from this speculation. On the contrary, one of the experiments in Wiegreffe and Pinter’s study, where they designed a transformer-like model with only one attention mechanism, does not raise this concern.
Experiment 2: the importance of sets of attention weights
In this experiment, authors begin erasing representation from the top of the ranking until the model’s decision changes. If there exists an alternative ranking where removing a smaller subset of items will change the decision, this means the candidate ranking is a poor indicator of importance. They make implicit assumptions that the best explanation is to the ranking that yields the smallest subset of features following the process, and the smaller the subset, the better the explanation. I do not find these two assumptions convincing.
The four settings are
- Random: random ranking
- Attention: ranking based on attention weights
- Gradient: ranking based on the gradient of model output with respect to attention weights
- Attn * Grad: ranking based on the product of the previous two options
Based on the results, the authors claim that they find better explanations than the one indicated by attention weights. Therefore, we should be skeptical about the notion of attention weights as importance indicators.
 Image source: [4]
Image source: [4]
Attention is not not Explanation
The paper [5] challenges many assumptions in Jain and Wallace’s paper [1] and proposes four alternative tests to determine when and whether attention can be used as an explanation.
- Is attention necessary? (A simple uniform-weights baseline, see Experiment 1.) Attentions cannot entail explanations if they are dispensable.
- How variant are attentions? (A variance calibration based on multiple random seed runs, see Experiment 2.) We need the baseline of attentions’ variation to adjust our perception accordingly
- is attention arbitrary/model-dependent? (A diagnostic framework using frozen weights from pretrained models, see Experiment 3.) If attentions are not model dependent so that they improve the performance of models of different structures, then they entail a certain level of “truth” or “explainability”
- An end-to-end adversarial attention training protocol
Premises in Jain and Wallace’s Paper
Premise 1: explainable attention distributions should be consistent with other feature-importance measures
Jain and Wallace find that attention is not strongly correlated with other feature importance metrics (gradient-based and leave-one-out methods), but the two feature importance metrics correlate well with each other. This set of experiments evaluate the claim of consistency. Wiegreffe and Pinter think this part is convincing since explainability of attention-based methods cannot be valid if they do not correlate well with other metrics. They seem to imply that moderate correlation is good enough.
Premise 2: explainable attention distributions should be exclusive
Jain and Wallace find that they can easily find a set of adversarial attentions that is very different from the original attention distributions but does not yield a significant change in outputs. In the paper [1], authors admit that it is possible that adversarial attentions uncover alternative and also plausible explanations, but they also point out that the existence of alternative explanations can be problematic in some applications. They impose the exclusivity requirement for explanations on this ground.
Rebuttal Arguments
Authors in this paper [5] question the experiment of adversarial attention for the following reasons.
Reason 1: attention distribution is not a primitive. Attention module is an integral part of the model. Detaching the attention scores degrades the model because it removes the influence of other parts of the model on the resultant attention distribution.
Reason 2: existence does not entail exclusivity. Attention can provide an explanation but not necessarily the explanation. In binary classifiers, prediction is reduced to a single scalar. Under this drastic reduction or aggregation, it is not surprising that it is easy to find many sets of adversarial attentions. Therefore, to establish a compelling argument against attentions as explanations, one needs to show that there exists an adversarial model that produces the claimed adversarial distributions and provides a baseline for variation of attention distribution (so that we know how adversarial the found adversarial distributions are).
Experiments
Experiment 1: is attention necessary?
If one forces the model to adopt uniform attention, then essentially the attention mechanism is turned off. If attention were important, one would expect a large drop in F1 scores. Authors deem in the last three tasks that attentions make trivial contributions. In future experiments, news data are dropped while SST is kept as a borderline.
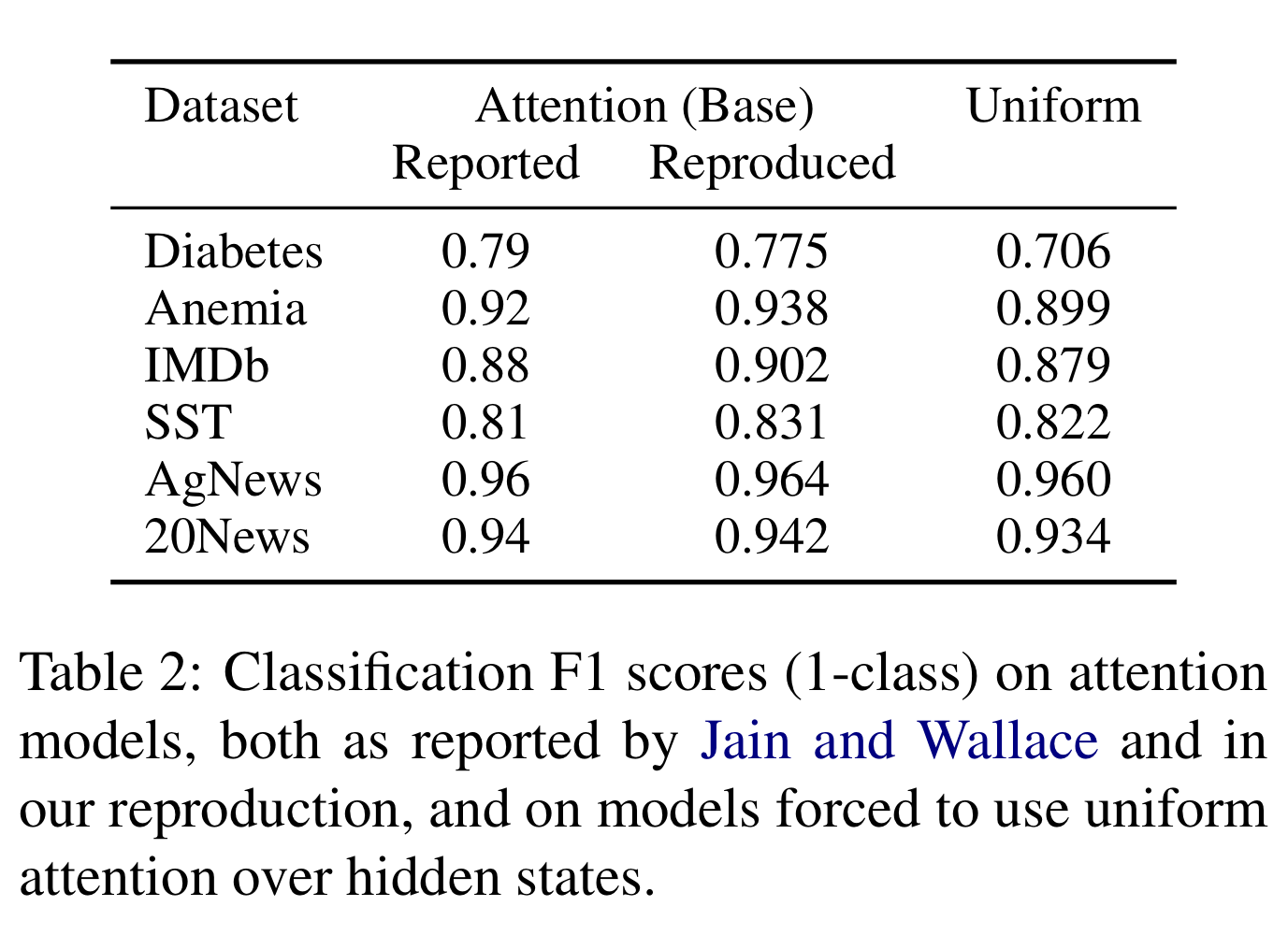 Image source: [5]
Image source: [5]
Experiment 2: how variant are attentions?
They repeat the training 8 times using different initialization seeds. This variance in the attention distributions is the baseline amount of variance and would be considered normal.
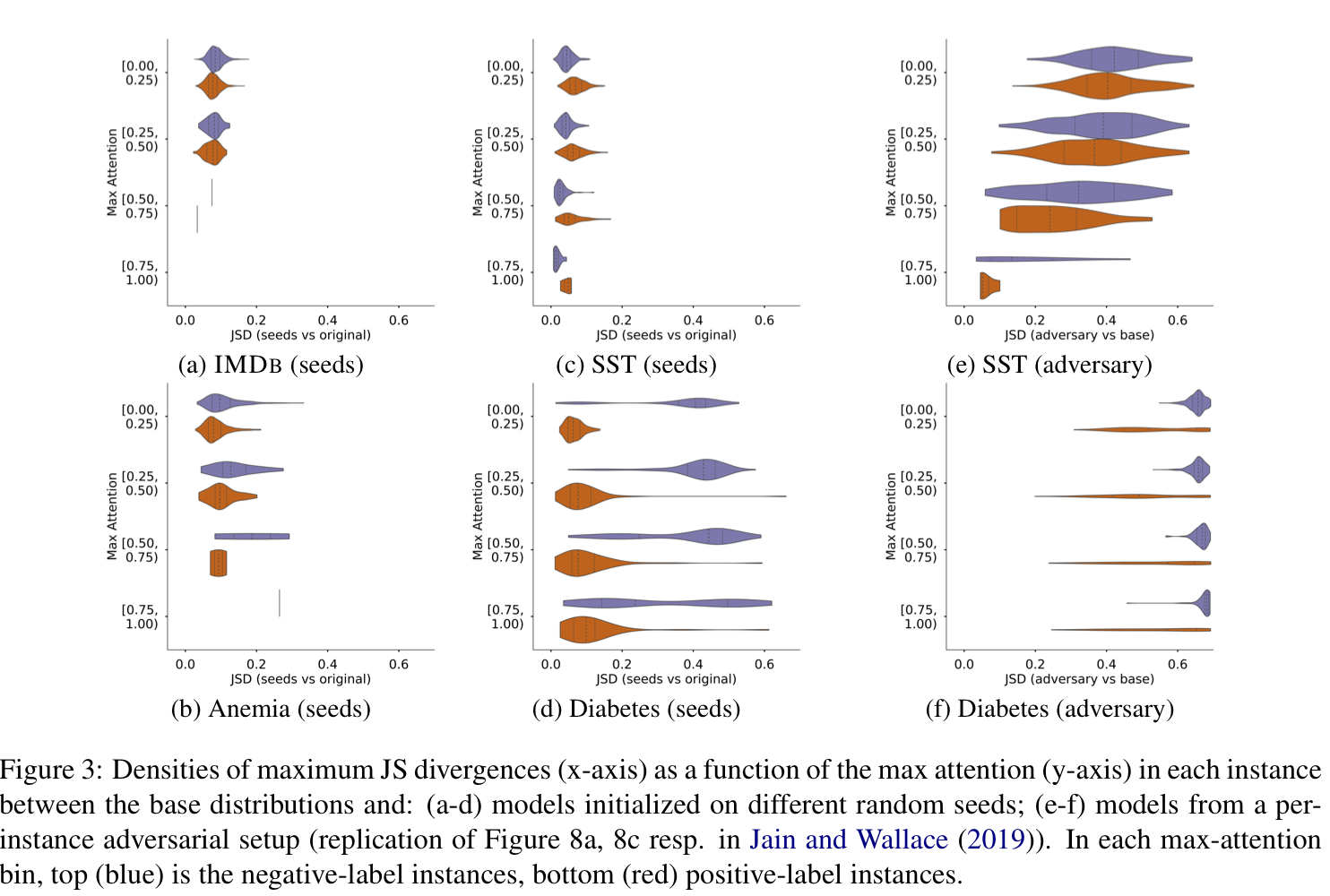 Image source: [5]
Image source: [5]
SST distributions (c,e) are very robust to random seed change. This means that even though the contribution of attention is insignificant, the attention distribution is not arbitrary. Therefore, the attention distributions on SST dataset are still interesting to look into. In the Diabetes dataset, the negative class is subject to arbitrary distributions (see (d)), making the counterpart in (f) less impressive.
Experiment 3: is attention arbitrary/model-dependent?
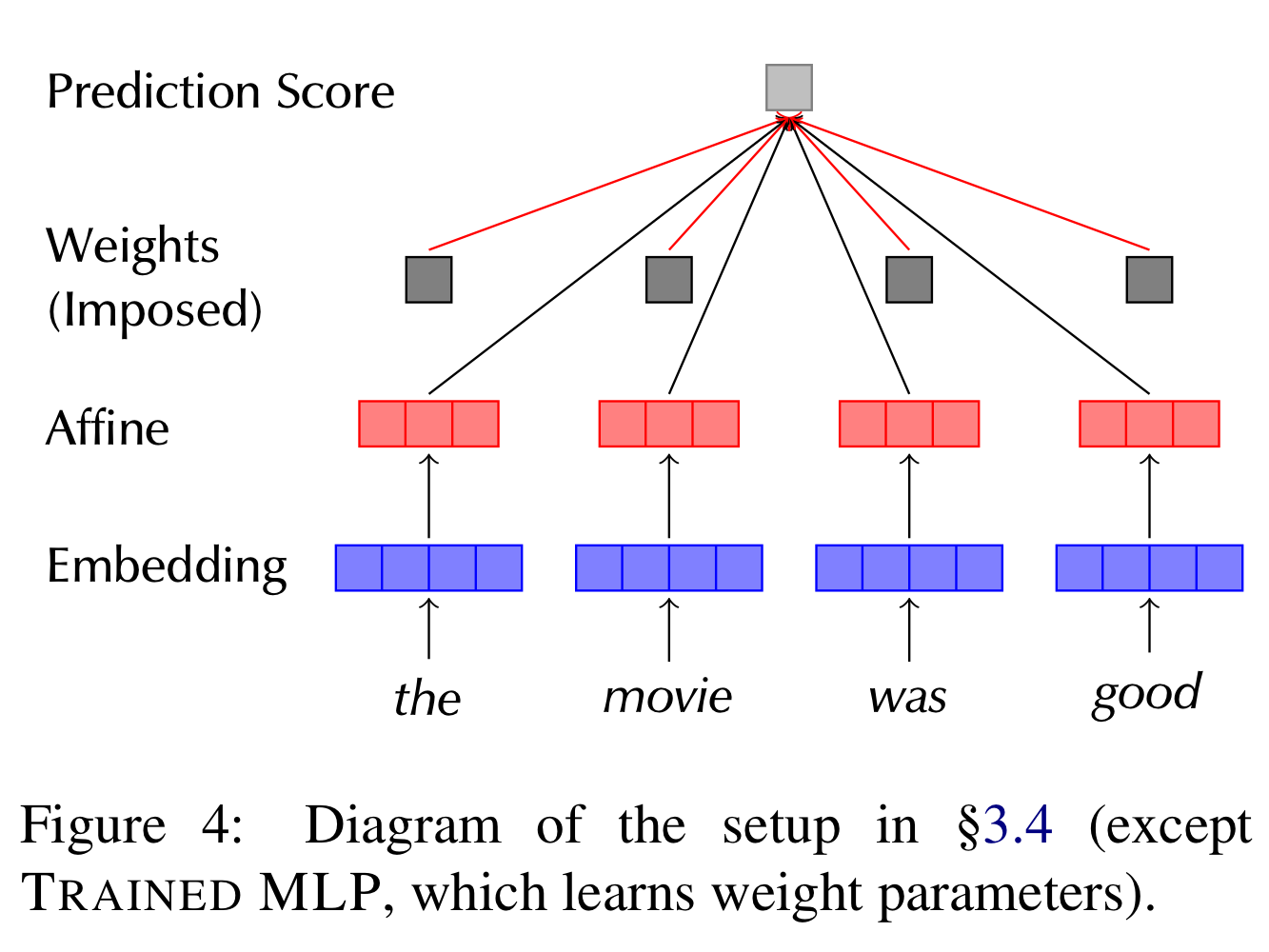 Image source: [5]
Image source: [5]
The setup of the model in this experiment is described as “a token-level affine hidden layer with tanh activation and forcing its output scores to be weighted by a pre-set, per-instance distribution”. Note that in this setting, attentions are primitive since they are imposed rather than generated internally so detaching them from the rest of the model will not degrade the model. This experiment design is motivated by the Reason 1 in the Rebuttal Arguments. Authors make an implication that if pre-trained attentions perform well, then attentions are deemed helpful and consistent, “fulfilling a certain sense of explainability.
They propose four weights distributions:
- Uniform, effectively unweighted
- Trained MLP, allowing MLP to learn its attention parameters and impose the learned attentions here
- Base LSTM, where attention distribution is taken from the base LSTM model’s attention layer
- Adversary, based on distributions found adversarially using the consistent training algorithm (See Experiment 4)
The results are shown in the table below.
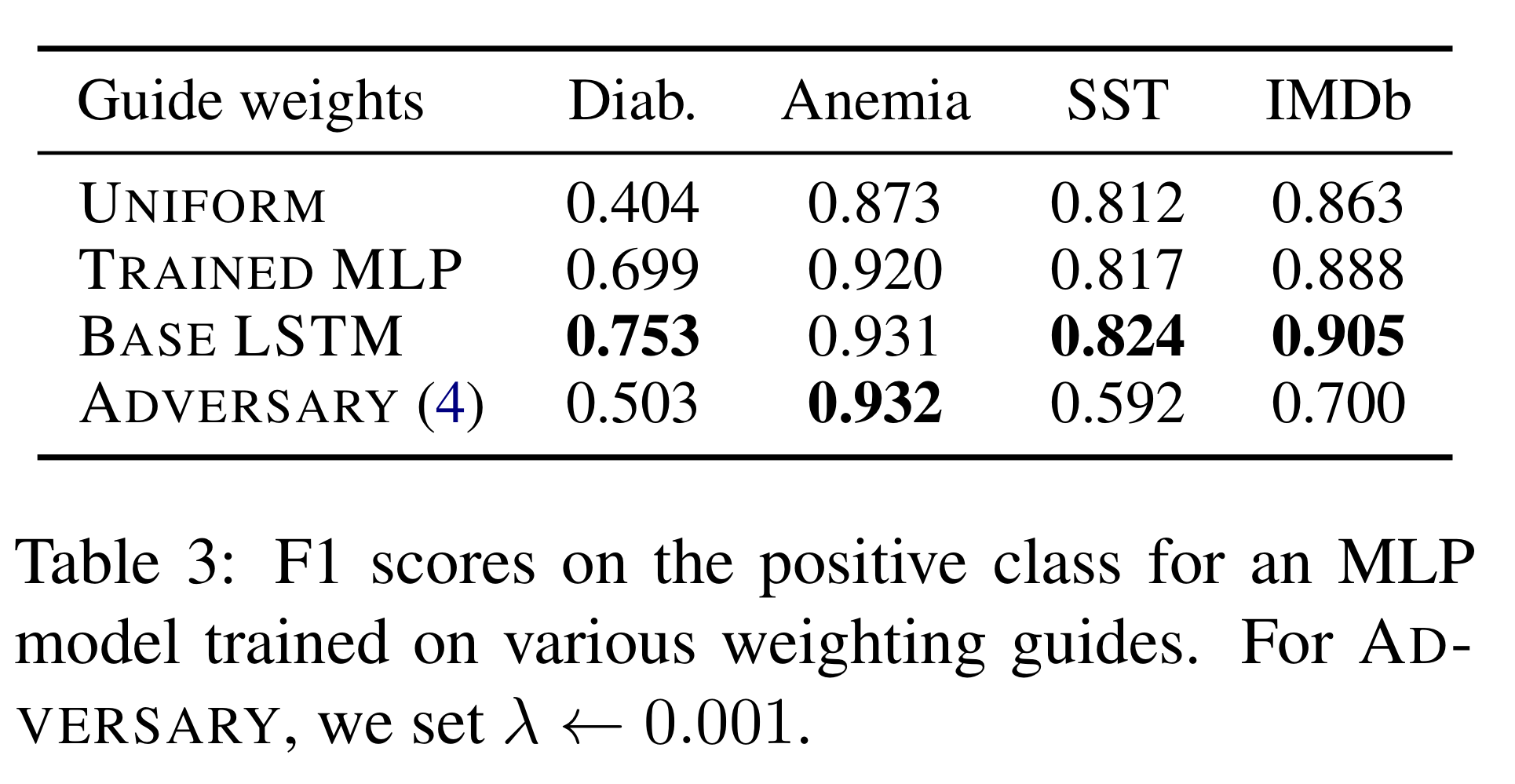 Image source: [5]
Image source: [5]
Observations
- Pretrained LSTM attention weights are better than letting the MLP learn them on its own
- Pretrained LSTM attention weights are in general better than adversary weights (except for the Anemia dataset, where authors conjecture that it is because the dataset is heavily skewed towards positive examples)
- Trained MLP attention weights are better than unweighted baseline
We can learn from the experiment results that attention weights are not arbitrary and not model-dependent.
Experiment 4: is attention easily manipulable? Is adversarial attention easy to find?
Given the base model
where
The TVD-JSD graph describes how will prediction similarity change as attention becomes increasingly dissimilar (recall that TVD describes divergence in predictions, and JSD describes that in attentions). As most curves are convex, which means dissimilar attentions tend to lead to dissimilar predictions, it shows attentions are NOT easily manipulable. (Original paper offers two contradictory interpretations on the shape of TVD-JSD curve. I think the interpretation in the TVD/JSE tradeoff section is right while that in Model section is misspelled) Additionally, the results from Jain and Wallace’s adversarial setup [1], indicated by a red plus sign, are located far below the adversarial setup in this paper [5]. Therefore, the authors conclude that Jain and Wallace’s per-instance setup is a considerable exaggeration.
Authors’ adversarial models reach comparable accuracy measured by F1 score, but when imposing adversarial attentions to Experiment 3, contrary to the fact that imposing attentions from the base LSTM model improves accuracy, adversarial attentions are “usually completely incapable of providing a non-contextual framework with useful guides”.
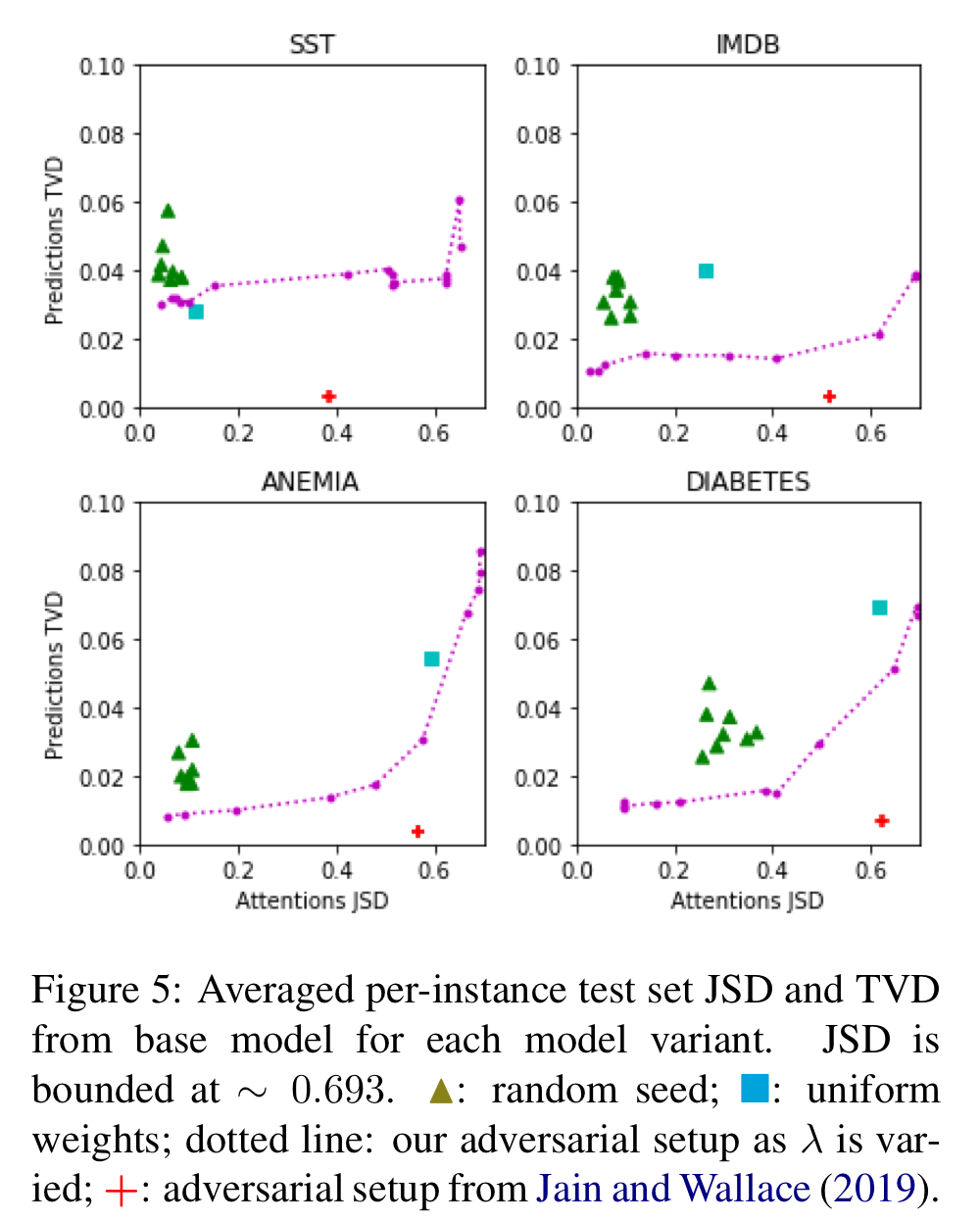 Image source: [5]
Image source: [5]
References
[1] S. Jain and B. C. Wallace, "Attention is not explanation," arXiv preprint arXiv:1902.10186, 2019.
[2] S. Feng, E. Wallace, A. Grissom II, M. Iyyer, P. Rodriguez, and J. Boyd-Graber, "Pathologies of neural models make interpretations difficult," arXiv preprint arXiv:1804.07781, 2018.
[3] A. S. Ross, M. C. Hughes, and F. Doshi-Velez, "Right for the right reasons: Training differentiable models by constraining their explanations," arXiv preprint arXiv:1703.03717, 2017.
[4] S. Serrano and N. A. Smith, "Is attention interpretable?," arXiv preprint arXiv:1906.03731, 2019.
[5] S. Wiegreffe and Y. Pinter, "Attention is not not explanation," arXiv preprint arXiv:1908.04626, 2019.
- Post title:The Attention Interpretability Debate
- Post author:Lutao Dai
- Create time:2021-12-15 19:37:54
- Post link:https://lutaodai.github.io/2021-12-25-attn-interpretability-debate/
- Copyright Notice:All articles in this blog are licensed under BY-NC-SA unless stating additionally.